Microsoft Azure Data Engineer Associate DP-203 Updated Dumps U2022.3
Earning the Microsoft Certified: Azure Data Engineer Associate certification requires you to successfully complete the DP-203 Data Engineering on Microsoft Azure exam.
No matter what stage you are in, use the DP-203 dumps as study material to ensure you pass the exam with ease during the preparation process. The latest DP-203 exam dumps offer 239 practice questions.
You can choose to use Leads4Pass DP-203 dumps with PDF and VCE: https://www.leads4pass.com/dp-203.html learning modes. Any mode will help you to study and pass the DP-203 Data Engineering on Microsoft Azure exam easily,
Earn the Microsoft Certified: Azure Data Engineer Associate certification.
Top Recommended Self-Test with Microsoft DP-203 Free Dumps U2022.3
PS. Participate in the test, check the answer at the end of the article
QUESTION 1
You have an enterprise data warehouse in Azure Synapse Analytics.
Using PolyBase, you create an external table named [Ext].[Items] to query Parquet files stored in Azure Data Lake Storage Gen2 without importing the data to the data warehouse.
The external table has three columns.
You discover that the Parquet files have a fourth column named ItemID.
Which command should you run to add the ItemID column to the external table?

A. Option A
B. Option B
C. Option C
D. Option D
Incorrect Answers:
A D: Only these Data Definition Language (DDL) statements are allowed on external tables:
1. CREATE TABLE and DROP TABLE
2. CREATE STATISTICS and DROP STATISTICS
3. CREATE VIEW and DROP VIEW
Reference: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-table-transact-sql
QUESTION 2
What should you recommend using to secure sensitive customer contact information?
A. Transparent Data Encryption (TDE)
B. row-level security
C. column-level security
D. data sensitivity labels
Scenario: All cloud data must be encrypted at rest and in transit.
Always Encrypted is a feature designed to protect sensitive data stored in specific database columns from access (for example, credit card numbers, national identification numbers, or data on a need-to-know basis). This includes database administrators or other privileged users who are authorized to access the database to perform management tasks but have no business need to access the particular data in the encrypted columns. The data is always encrypted, which means the encrypted data is decrypted only for processing by client applications with access to the encryption key.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-security-overview
QUESTION 3
HOTSPOT
You build an Azure Data Factory pipeline to move data from an Azure Data Lake Storage Gen2 container to a database in an Azure Synapse Analytics dedicated SQL pool.
Data in the container is stored in the following folder structure.
/in/{YYYY}/{MM}/{DD}/{HH}/{mm}
The earliest folder is /in/2021/01/01/00/00. The latest folder is /in/2021/01/15/01/45.
You need to configure a pipeline trigger to meet the following requirements:
Existing data must be loaded.
Data must be loaded every 30 minutes.
Late-arriving data of up to two minutes must be included in the load for the time at which the data should have arrived.
How should you configure the pipeline trigger? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
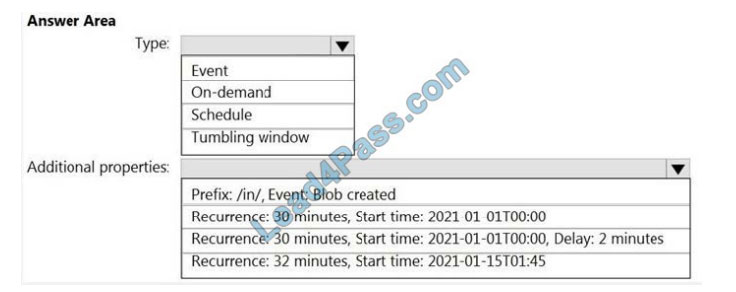
Correct Answer:
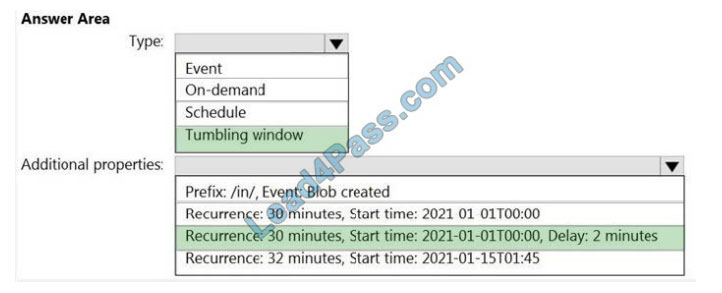
Box 1: Tumbling window
To be able to use the Delay parameter we select the Tumbling window.
Box 2: Recurrence: 30 minutes, not 32 minutes
Delay: 2 minutes.
The amount of time to delay the start of data processing for the window. The pipeline run is started after the expected execution time plus the amount of delay. The delay defines how long the trigger waits past the due time before triggering a new run. The delay doesn\’t alter the window start time.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-tumbling-window-trigger
QUESTION 4
You need to design a solution that will process streaming data from an Azure Event Hub and output the data to Azure Data Lake Storage. The solution must ensure that analysts can interactively query the streaming data. What should you use?
A. event triggers in Azure Data Factory
B. Azure Stream Analytics and Azure Synapse notebooks
C. Structured Streaming in Azure Databricks
D. Azure Queue storage and read-access geo-redundant storage (RA-GRS)
QUESTION 5
DRAG-DROP
You are responsible for providing access to an Azure Data Lake Storage Gen2 account.
Your user account has contributor access to the storage account, and you have the application ID and access key.
You plan to use PolyBase to load data into an enterprise data warehouse in Azure Synapse Analytics.
You need to configure PolyBase to connect the data warehouse to the storage account.
Which three components should you create in sequence? To answer, move the appropriate components from the list of components to the answer area and arrange them in the correct order.
Select and Place:
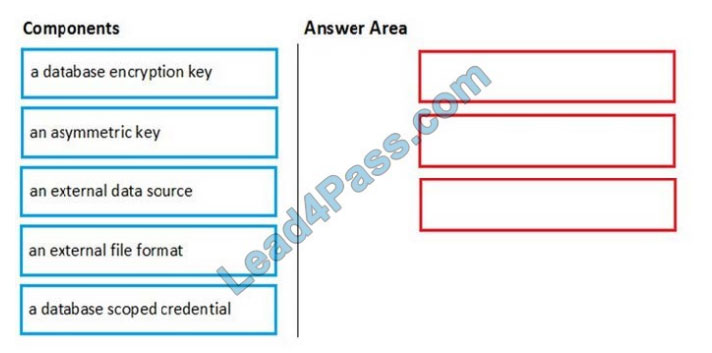
Correct Answer:
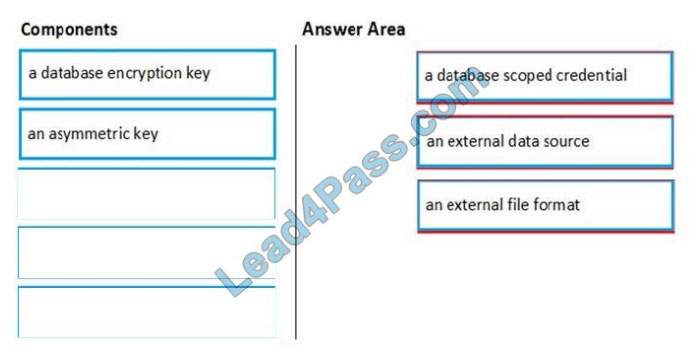
Step 1: a database scoped credential
To access your Data Lake Storage account, you will need to create a Database Master Key to encrypt your credential secret used in the next step. You then create a database scoped credential.
Step 2: an external data source Create the external data source. Use the CREATE EXTERNAL DATA SOURCE command to store the location of the data. Provide the credential created in the previous step.
Step 3: an external file format Configure data format: To import the data from Data Lake Storage, you need to specify the External File Format. This object defines how the files are written in Data Lake Storage.
QUESTION 6
You are designing a streaming data solution that will ingest variable volumes of data.
You need to ensure that you can change the partition count after creation.
Which service should you use to ingest the data?
A. Azure Event Hubs Dedicated
B. Azure Stream Analytics
C. Azure Data Factory
D. Azure Synapse Analytics
You can\’t change the partition count for an event hub after its creation except for the event hub in a dedicated cluster.
Reference: https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-features
QUESTION 7
You have an Azure Synapse Analytics dedicated SQL pool mat containing a table named dbo.Users.
You need to prevent a group of users from reading user email addresses from dbo.Users. What should you use?
A. row-level security
B. column-level security
C. Dynamic data masking
D. Transparent Data Encryption (TDD
QUESTION 8
You have several Azure Data Factory pipelines that contain a mix of the following types of activities.
1. Wrangling data flow
2. Notebook
3. Copy
4. jar
Which two Azure services should you use to debug the activities?
Each correct answer presents part of the solution
NOTE: Each correct selection is worth one point.
A. Azure HDInsight
B. Azure Databricks
C. Azure Machine Learning
D. Azure Data Factory
E. Azure Synapse Analytics
QUESTION 9
You are monitoring an Azure Stream Analytics job.
You discover that the Backlogged Input Events metric is increasing slowly and is consistently non-zero.
You need to ensure that the job can handle all the events.
What should you do?
A. Change the compatibility level of the Stream Analytics job.
B. Increase the number of streaming units (SUs).
C. Remove any named consumer groups from the connection and use $default.
D. Create an additional output stream for the existing input stream.
Backlogged Input Events: Number of input events that are backlogged. A non-zero value for this metric implies that your job isn\’t able to keep up with the number of incoming events. If this value is slowly increasing or consistently non-zero, you should scale out your job. You should increase the Streaming Units.
Note: Streaming Units (SUs) represent the computing resources that are allocated to execute a Stream Analytics job.
The higher the number of SUs, the more CPU and memory resources are allocated for your job.
Reference: https://docs.microsoft.com/bs-cyrl-ba/azure/stream-analytics/stream-analytics-monitoring
QUESTION 10
You have the following Azure Data Factory pipelines:
1. Ingest Data from System1
2. Ingest Data from System2
3. Populate Dimensions
4. Populate Facts
Ingest Data from System1 and Ingest Data from System2 have no dependencies. Populate Dimensions must execute after Ingest Data from System1 and Ingest Data from System2. Populate Facts must execute after Populate Dimensions pipeline. All the pipelines must execute every eight hours.
What should you do to schedule the pipelines for execution?
A. Add an event trigger to all four pipelines.
B. Add a schedule trigger to all four pipelines.
C. Create a patient pipeline that contains the four pipelines and use a schedule trigger.
D. Create a patient pipeline that contains the four pipelines and use an event trigger.
Schedule Trigger: A trigger that invokes a pipeline on a wall-clock schedule.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/concepts-pipeline-execution-triggers
QUESTION 11
You have an Azure Databricks workspace named workspace1 in the Standard pricing tier.
You need to configure workspace1 to support autoscaling all-purpose clusters. The solution must meet the following requirements:
Automatically scale down workers when the cluster is underutilized for three minutes.
Minimize the time it takes to scale to the maximum number of workers.
Minimize costs.
What should you do first?
A. Enable container services for workspace1.
B. Upgrade workspace1 to the Premium pricing tier.
C. Set Cluster-Mode to High Concurrency.
D. Create a cluster policy in workspace1.
For clusters running Databricks Runtime 6.4 and above, optimized autoscaling is used by all-purpose clusters in the Premium plan Optimized autoscaling:
Scales up from min to max in 2 steps.
Can scale down even if the cluster is not idle by looking at shuffle file state.
Scales down based on a percentage of current nodes.
On job clusters, scales down if the cluster is underutilized over the last 40 seconds.
On all-purpose clusters, scales down if the cluster is underutilized over the last 150 seconds.
The spark. data bricks.aggressiveWindowDownS Spark configuration property specifies in seconds how often a cluster makes down-scaling decisions. Increasing the value causes a cluster to scale down more slowly. The maximum value is 600.
Note: Standard autoscaling
Starts with adding 8 nodes. Thereafter, scales up exponentially, but can take many steps to reach the max. You can customize the first step by setting the spark.data bricks.autoscaling.standardFirstStepUp Spark configuration property.
Scales down only when the cluster is completely idle and it has been underutilized for the last 10 minutes. Scales down exponentially, starting with 1 node.
Reference:
https://docs.databricks.com/clusters/configure.html
QUESTION 12
You have an Azure Synapse Analytics dedicated SQL pool that contains a large fact table. The table contains 50 columns and 5 billion rows and is a heap.
Most queries against the table aggregate values from approximately 100 million rows and return only two columns.
You discover that the queries against the fact table are very slow.
Which type of index should you add to provide the fastest query times?
A. nonclustered column store
B. clustered column store
C. nonclustered
D. clustered
Clustered columnstore indexes are one of the most efficient ways you can store your data in a dedicated SQL pool. Columnstore tables won\’t benefit a query unless the table has more than 60 million rows.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/best-practices-dedicated-sql-pool
Verify DP-203 Test Answers:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 |
| C | C | IMAGE | B | IMAGE | A | B | CE | B | C | B | B |
Microsoft DP-203 Free Dumps Share with questions and answers using PDF: https://drive.google.com/file/d/1lmORB29ba3eE_OhIslaaRBlVJb1tCH9o/view?usp=sharing
Use Leads4Pass DP-203 dumps with PDF and VCE: https://www.leads4pass.com/dp-203.html as study materials to ensure you pass the exam with ease.
