[11-Sep-2021 Update] Data Engineering on Microsoft Azure Exam DP-203 VCE Dumps and DP-203 PDF Dumps from Leads4Pass
New and Valid for 100% Passing Ensure Data Engineering on Microsoft Azure DP-203 Dumps from leads4pass: https://www.leads4pass.com/dp-203.html (214 Q&As),
leads4pass offers both DP-203 VCE Dumps and DP-203 PDF Dumps for Preparing for the Data Engineering on Microsoft Azure DP-203 Exam, 100% Valid and 100% Passing Guarantee.
More, you can download the latest leads4pass DP-203 Exam Dumps Online for FREE: https://drive.google.com/file/d/1xN5EN2v9JWB89rjPFLPmTJFHaWfAfIQd/
Free Data Engineering on Microsoft Azure DP-203 exam questions and answers
QUESTION 1
You are designing an Azure Databricks table. The table will ingest an average of 20 million streaming events per day.
You need to persist the events in the table for use in incremental load pipeline jobs in Azure Databricks. The solution
must minimize storage costs and incremental load times.
What should you include in the solution?
A. Partition by DateTime fields.
B. Sink to Azure Queue storage.
C. Include a watermark column.
D. Use a JSON format for physical data storage.
Correct Answer: B
The Databricks ABS-AQS connector uses Azure Queue Storage (AQS) to provide an optimized file source that lets you
find new files written to an Azure Blob storage (ABS) container without repeatedly listing all of the files. This provides
two major advantages:
Lower latency: no need to list nested directory structures on ABS, which is slow and resource intensive.
Lower costs: no more costly LIST API requests made to ABS.
Reference:
https://docs.microsoft.com/en-us/azure/databricks/spark/latest/structured-streaming/aqs
QUESTION 2
DRAG DROP
You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two
attributes named FirstName and LastName.
You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new
column must be created that concatenates the FirstName and LastName values.
You create the following components:
A destination table in Azure Synapse An Azure Blob storage container A service principal
Which five actions should you perform in sequence next in is Databricks notebook? To answer, move the appropriate
actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place:
Step 1: Read the file into a data frame.
You can load the json files as a data frame in Azure Databricks.
Step 2: Perform transformations on the data frame.
Step 3:Specify a temporary folder to stage the data
Specify a temporary folder to use while moving data between Azure Databricks and Azure Synapse.
Step 4: Write the results to a table in Azure Synapse.
You upload the transformed data frame into Azure Synapse. You use the Azure Synapse connector for Azure
Databricks to directly upload a dataframe as a table in a Azure Synapse.
Step 5: Drop the data frame
Clean up resources. You can terminate the cluster. From the Azure Databricks workspace, select Clusters on the left.
For the cluster to terminate, under Actions, point to the ellipsis (…) and select the Terminate icon.
Reference:
https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-extract-load-sql-data-warehouse
QUESTION 3
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only
once.
Solution: You use a session window that uses a timeout size of 10 seconds.
Does this meet the goal?
A. Yes
B. No
Correct Answer: B
Instead use a tumbling window. Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time
intervals.
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
QUESTION 4
You have a table in an Azure Synapse Analytics dedicated SQL pool. The table was created by using the following
Transact-SQL statement.

You need to alter the table to meet the following requirements:
Ensure that users can identify the current manager of employees.
Support creating an employee reporting hierarchy for your entire company.
Provide fast lookup of the managers\\’ attributes such as name and job title.
Which column should you add to the table?
A. [ManagerEmployeeID] [int] NULL
B. [ManagerEmployeeID] [smallint] NULL
C. [ManagerEmployeeKey] [int] NULL
D. [ManagerName] [varchar](200) NULL
Correct Answer: A
Use the same definition as the EmployeeID column.
Reference: https://docs.microsoft.com/en-us/analysis-services/tabular-models/hierarchies-ssas-tabular
QUESTION 5
You have two Azure Data Factory instances named ADFdev and ADFprod. ADFdev connects to an Azure DevOps Git
repository.
You publish changes from the main branch of the Git repository to ADFdev.
You need to deploy the artifacts from ADFdev to ADFprod.
What should you do first?
A. From ADFdev, modify the Git configuration.
B. From ADFdev, create a linked service.
C. From Azure DevOps, create a release pipeline.
D. From Azure DevOps, update the main branch.
Correct Answer: C
In Azure Data Factory, continuous integration and delivery (CI/CD) means moving Data Factory pipelines from one
environment (development, test, production) to another.
Note:
The following is a guide for setting up an Azure Pipelines release that automates the deployment of a data factory to
multiple environments.
1.
In Azure DevOps, open the project that\\’s configured with your data factory.
2.
On the left side of the page, select Pipelines, and then select Releases.
3.
Select New pipeline, or, if you have existing pipelines, select New and then New release pipeline.
4.
In the Stage name box, enter the name of your environment.
5.
Select Add artifact, and then select the git repository configured with your development data factory. Select the publish
branch of the repository for the Default branch. By default, this publish branch is adf_publish.
6.
Select the Empty job template.
Reference: https://docs.microsoft.com/en-us/azure/data-factory/continuous-integration-deployment
QUESTION 6
DRAG DROP
You have an Azure data factory.
You need to ensure that pipeline-run data is retained for 120 days. The solution must ensure that you can query the
data by using the Kusto query language.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Select and Place:

Correct Answer:
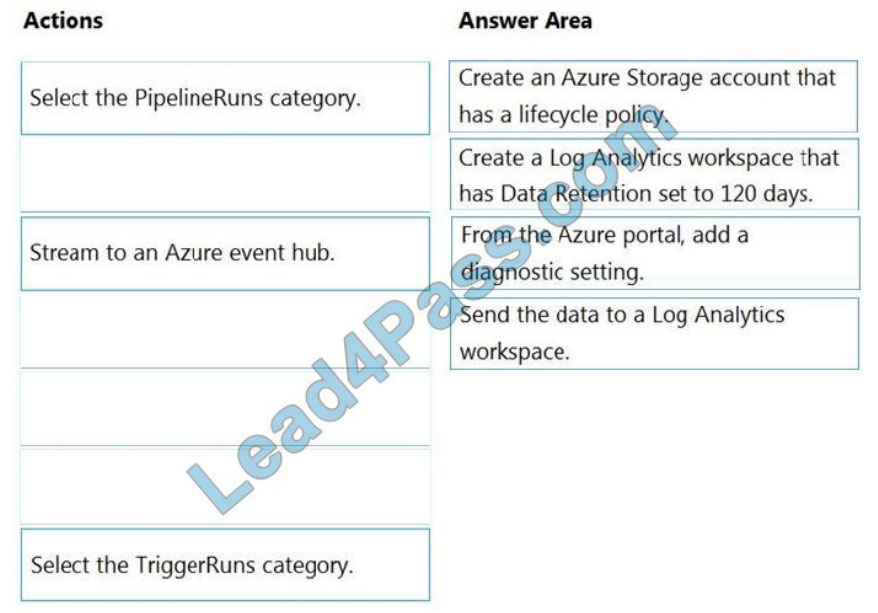
Step 1: Create an Azure Storage account that has a lifecycle policy
To automate common data management tasks, Microsoft created a solution based on Azure Data Factory. The service,
Data Lifecycle Management, makes frequently accessed data available and archives or purges other data according to
retention policies. Teams across the company use the service to reduce storage costs, improve app performance, and
comply with data retention policies.
Step 2: Create a Log Analytics workspace that has Data Retention set to 120 days.
Data Factory stores pipeline-run data for only 45 days. Use Azure Monitor if you want to keep that data for a longer
time. With Monitor, you can route diagnostic logs for analysis to multiple different targets, such as a Storage Account:
Save
your diagnostic logs to a storage account for auditing or manual inspection. You can use the diagnostic settings to
specify the retention time in days.
Step 3: From Azure Portal, add a diagnostic setting.
Step 4: Send the data to a log Analytics workspace,
Event Hub: A pipeline that transfers events from services to Azure Data Explorer.
Keeping Azure Data Factory metrics and pipeline-run data.
Configure diagnostic settings and workspace.
Create or add diagnostic settings for your data factory.
In the portal, go to Monitor. Select Settings > Diagnostic settings.
Select the data factory for which you want to set a diagnostic setting.
If no settings exist on the selected data factory, you\\’re prompted to create a setting. Select Turn on diagnostics.
Give your setting a name, select Send to Log Analytics, and then select a workspace from Log Analytics Workspace.
Select Save.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
QUESTION 7
You are designing an Azure Stream Analytics solution that will analyze Twitter data.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only
once.
Solution: You use a tumbling window, and you set the window size to 10 seconds.
Does this meet the goal?
A. Yes
B. No
Correct Answer: A
Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. The following diagram
illustrates a stream with a series of events and how they are mapped into 10-second tumbling windows.
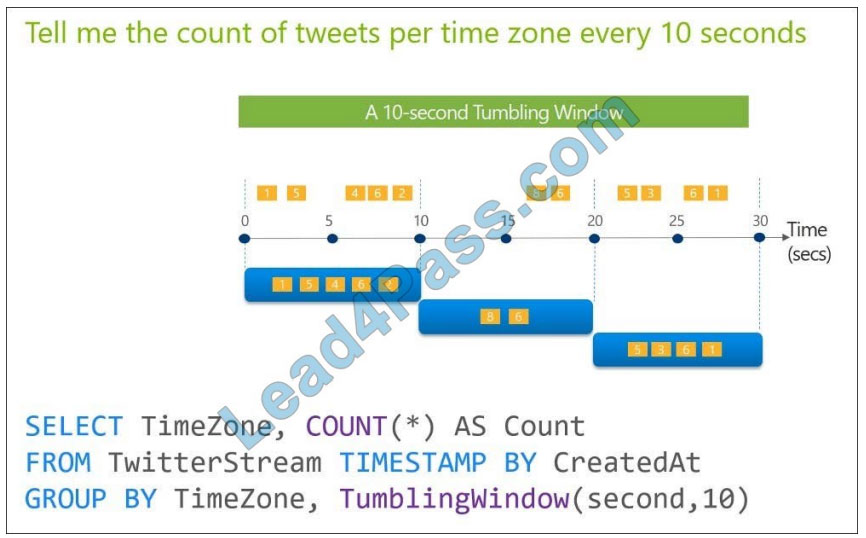
Reference: https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
QUESTION 8
HOTSPOT
You are building an Azure Stream Analytics job to identify how much time a user spends interacting with a feature on a
webpage.
The job receives events based on user actions on the webpage. Each row of data represents an event. Each event has
a type of either \\’start\\’ or \\’end\\’.
You need to calculate the duration between start and end events.
How should you complete the query? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: DATEDIFF
DATEDIFF function returns the count (as a signed integer value) of the specified datepart boundaries crossed between
the specified startdate and enddate.
Syntax: DATEDIFF ( datepart , startdate, enddate )
Box 2: LAST
The LAST function can be used to retrieve the last event within a specific condition. In this example, the condition is an
event of type Start, partitioning the search by PARTITION BY user and feature. This way, every user and feature is
treated independently when searching for the Start event. LIMIT DURATION limits the search back in time to 1 hour
between the End and Start events.
Example:
SELECT [user], feature, DATEDIFF( second, LAST(Time) OVER (PARTITION BY [user], feature LIMIT
DURATION(hour, 1) WHEN Event = \\’start\\’), Time) as duration
FROM input TIMESTAMP BY Time
WHERE Event = \\’end\\’
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-stream-analytics-query-patterns
QUESTION 9
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following
three workloads:
A workload for data engineers who will use Python and SQL.
A workload for jobs that will run notebooks that use Python, Scala, and SOL.
A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data scientists and data engineers provide
packaged notebooks for deployment to the cluster.
All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity.
Currently, there are three data scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a
High Concurrency cluster for the jobs.
Does this meet the goal?
A. Yes
B. No
Correct Answer: A
We need a High Concurrency cluster for the data engineers and the jobs.
Note:
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python,
R, Scala, and SQL.
A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they
provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
Reference:
https://docs.azuredatabricks.net/clusters/configure.html
QUESTION 10
You have an enterprise-wide Azure Data Lake Storage Gen2 account. The data lake is accessible only through an
Azure virtual network named VNET1.
You are building a SQL pool in Azure Synapse that will use data from the data lake.
Your company has a sales team. All the members of the sales team are in an Azure Active Directory group named
Sales. POSIX controls are used to assign the Sales group access to the files in the data lake.
You plan to load data to the SQL pool every hour.
You need to ensure that the SQL pool can load the sales data from the data lake.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each area selection is worth one point.
A. Add the managed identity to the Sales group.
B. Use the managed identity as the credentials for the data load process.
C. Create a shared access signature (SAS).
D. Add your Azure Active Directory (Azure AD) account to the Sales group.
E. Use the snared access signature (SAS) as the credentials for the data load process.
F. Create a managed identity.
Correct Answer: ADF
The managed identity grants permissions to the dedicated SQL pools in the workspace.
Note: Managed identity for Azure resources is a feature of Azure Active Directory. The feature provides Azure services
with an automatically managed identity in Azure AD
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/security/synapse-workspace-managed-identity
QUESTION 11
You plan to create an Azure Databricks workspace that has a tiered structure. The workspace will contain the following
three workloads:
A workload for data engineers who will use Python and SQL.
A workload for jobs that will run notebooks that use Python, Scala, and SOL.
A workload that data scientists will use to perform ad hoc analysis in Scala and R.
The enterprise architecture team at your company identifies the following standards for Databricks environments:
The data engineers must share a cluster.
The job cluster will be managed by using a request process whereby data scientists and data engineers provide
packaged notebooks for deployment to the cluster.
All the data scientists must be assigned their own cluster that terminates automatically after 120 minutes of inactivity.
Currently, there are three data scientists.
You need to create the Databricks clusters for the workloads.
Solution: You create a Standard cluster for each data scientist, a High Concurrency cluster for the data engineers, and a
Standard cluster for the jobs. Does this meet the goal?
A. Yes
B. No
Correct Answer: B
We would need a High Concurrency cluster for the jobs.
Note:
Standard clusters are recommended for a single user. Standard can run workloads developed in any language: Python,
R, Scala, and SQL.
A high concurrency cluster is a managed cloud resource. The key benefits of high concurrency clusters are that they
provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies.
Reference:
https://docs.azuredatabricks.net/clusters/configure.html
QUESTION 12
What should you recommend using to secure sensitive customer contact information?
A. Transparent Data Encryption (TDE)
B. row-level security
C. column-level security
D. data sensitivity labels
Correct Answer: D
Scenario: Limit the business analysts
QUESTION 13
DRAG DROP
You have an Azure Stream Analytics job that is a Stream Analytics project solution in Microsoft Visual Studio. The job
accepts data generated by IoT devices in the JSON format.
You need to modify the job to accept data generated by the IoT devices in the Protobuf format.
Which three actions should you perform from Visual Studio on sequence? To answer, move the appropriate actions
from the list of actions to the answer area and arrange them in the correct order.
Select and Place:

Correct Answer:

QUESTION 14
HOTSPOT
You have an Azure event hub named retailhub that has 16 partitions. Transactions are posted to retailhub. Each
transaction includes the transaction ID, the individual line items, and the payment details. The transaction ID is used as
the partition key. You are designing an Azure Stream Analytics job to identify potentially fraudulent transactions at a
retail store. The job will use retailhub as the input. The job will output the transaction ID, the individual line items, the
payment details, a fraud
score, and a fraud indicator.
You plan to send the output to an Azure event hub named fraudhub.
You need to ensure that the fraud detection solution is highly scalable and processes transactions as quickly as
possible.
How should you structure the output of the Stream Analytics job? To answer, select the appropriate options in the
answer area.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:
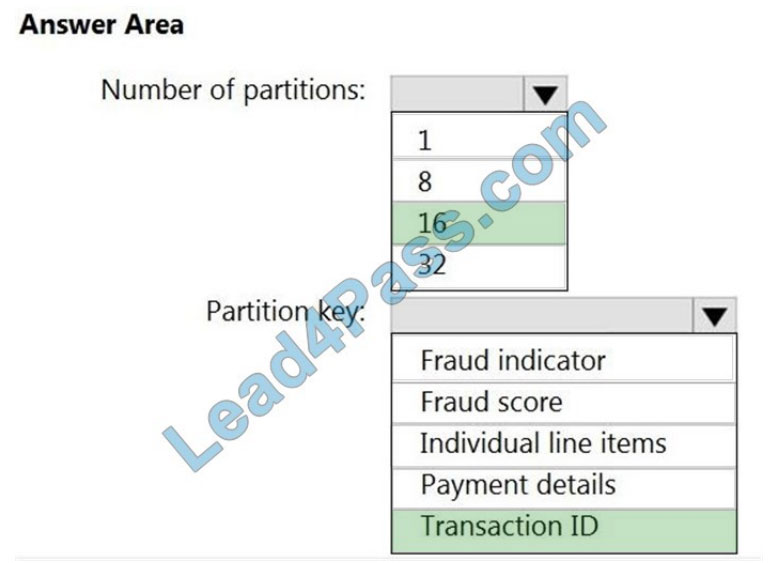
Box 1: 16
For Event Hubs you need to set the partition key explicitly.
An embarrassingly parallel job is the most scalable scenario in Azure Stream Analytics. It connects one partition of the
input to one instance of the query to one partition of the output.
Box 2: Transaction ID
Reference:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-features#partitions
QUESTION 15
DRAG DROP
You need to create a partitioned table in an Azure Synapse Analytics dedicated SQL pool.
How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets.
Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll
to view content.
NOTE: Each correct selection is worth one point.
Select and Place:
Correct Answer:

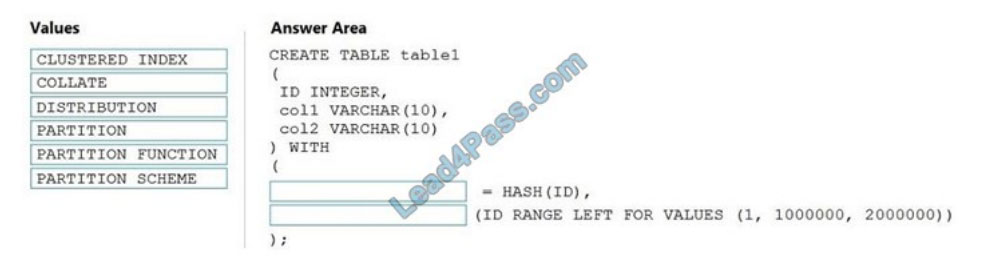
Box 1: DISTRIBUTION
Table distribution options include DISTRIBUTION = HASH ( distribution_column_name ), assigns each row to one
distribution by hashing the value stored in distribution_column_name.
Box 2: PARTITION
Table partition options. Syntax:
PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [,…n] ] ))
Reference:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-table-azure-sql-data-warehouse?
Continue to follow to get more free updates…
Trying the leads4pass DP-203 Dumps in VCE and PDF for Your First Attempt and 100% Passing: https://www.leads4pass.com/dp-203.html (214 Q&As, VCE, and PDF)
More, download new leads4pass DP-203 Exam Dumps for FREE: https://drive.google.com/file/d/1xN5EN2v9JWB89rjPFLPmTJFHaWfAfIQd/
