DP-600 in 2026: What Changed and How to Pass
In early 2026, Microsoft made a few minor yet important updates to the DP-600 exam, also known as the Fabric Analytics Engineer certification. If you’re working in data analytics or looking to transition into a Fabric-related role, it’s essential to know what changed and how these updates affect your exam preparation. In this post, I’ll walk you through the steps to pass the exam, highlight the latest exam updates, and share practical strategies to help you achieve a strong result. I also previously shared an article titled “How to Pass the Microsoft DP-600 Exam,” which you may find helpful to read alongside this one for comparison.
What’s New in the DP-600 Exam for 2026?

Exam Updates: Key Changes in 2026
The most notable changes in the DP-600 exam revolve around a few refined descriptions and additional focus areas. The core topics like deployment pipelines, governance, and reusable assets have been better clarified. Here’s what you need to focus on:
- Governance and Compliance: The importance of security and compliance, particularly with data governance in Fabric environments, has been highlighted.
- Deployment Pipelines: Updates now give more emphasis on mastering the continuous deployment and monitoring pipelines within the Fabric environment.
- Reusable Assets: Understanding how reusable components can optimize development in Fabric is now a priority.
These updates reflect the industry’s shift toward a more robust, scalable analytics environment with better governance and automation features.
Refined Skills Measured for the DP-600 Exam
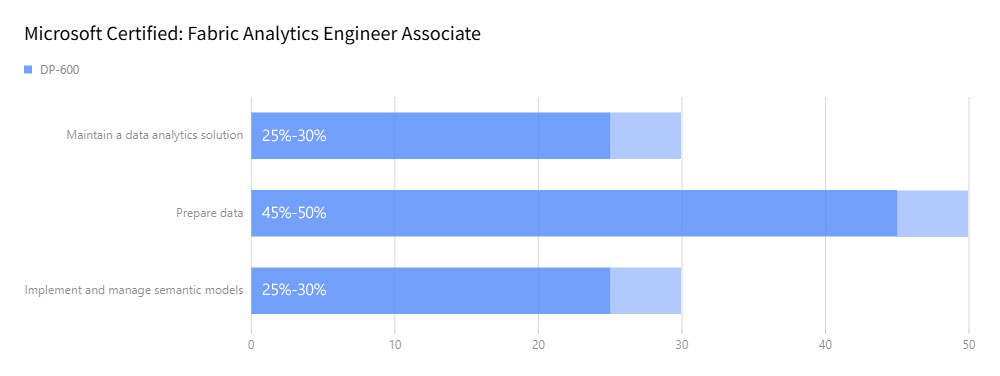
While the general structure of the exam has remained the same, the weighting of topics has been slightly adjusted. Below is the updated breakdown:
- Prepare Data (45-50%): This still represents the majority of the exam. Focus on data ingestion, transformation, and working with Direct Lake.
- Maintain Solutions (25-30%): This section includes managing, optimizing, and troubleshooting deployed solutions.
- Semantic Models (25-30%): Key topics here involve data models and advanced analytic functions, including row-level security and other design elements.
The Best Preparation Path for DP-600 in 2026

Step 1: Start with Microsoft Learn
For a structured approach to studying, begin with Microsoft Learn modules tailored to the DP-600 exam. These modules offer free, comprehensive content that aligns with the current exam objectives. Make sure to check for the latest updates in the learning paths, as Microsoft frequently refreshes them to reflect the most relevant industry trends.
Step 2: Get Hands-On Experience
The theoretical knowledge from Microsoft Learn is invaluable, but nothing beats hands-on experience. Microsoft Fabric is complex, and real-world practice is necessary to truly understand how the components work.
- Experiment with Direct Lake: Set up a Direct Lake instance, work through transformations, and get comfortable with the performance monitoring tools.
- Play with Deployment Pipelines: Setting up CI/CD pipelines in Fabric is crucial. Work with deployment environments to understand how automation impacts the workflow.
Step 3: Practice with Targeted Simulations
After your learning and practice sessions, it’s time to test yourself. Use practice exams, including the official Microsoft DP-600 sample tests, to identify areas of weakness.
The Exam Breakdown: Key Focus Areas in 2026
Prepare Data (45-50%)
This section is the largest portion of the exam, focusing on your ability to prepare and manage data within the Fabric environment.
- Data Ingestion: Be familiar with the various methods of ingesting data into Fabric, including batch processing, streaming, and using external data connectors.
- Data Transformation: Understand the transformation pipeline and how to use Fabric’s built-in tools to manipulate and clean data.
- Direct Lake Fallback: One of the newer focuses in 2026 is Direct Lake fallback. This method enables seamless data access even when connections fail. Understand the configurations and best practices.
Maintain Solutions (25-30%)
Once data is prepared, maintaining solutions ensures everything runs smoothly. This section focuses on troubleshooting, monitoring, and optimizing solutions deployed in Fabric.
- Solution Monitoring: Learn how to set up alerts, monitor performance, and optimize resource allocation in a Fabric environment.
- Data Integrity: Understand how to maintain data consistency, especially when working with large-scale datasets.
Semantic Models (25-30%)
This portion of the exam tests your understanding of semantic models and their application in analytics.
- Row-Level Security: Be prepared to implement and troubleshoot row-level security in Fabric. This is vital for creating secure models.
- Advanced Analytics: Focus on creating complex semantic models that include aggregations, calculations, and leveraging DAX (Data Analysis Expressions) for custom metrics.
Free and Paid Resources to Help You Prepare

Free Practice Questions
I’ve put together a fresh set of 10+ practice questions based on the 2026 skills measured. These reflect the current focus areas of the DP-600 exam and helped me solidify weak spots. You can download the PDF here: [https://drive.google.com/file/d/1lhzxJGQquT-nlUMki44OuHZdYP1GA46m/view?usp=sharing].
Paid Resources
While free resources are great, paid resources like Leads4Pass offer additional practice questions and study materials. Their DP-600 dumps collection has been quite helpful for many exam takers.
Career Impact: What Does the DP-600 Certification Mean?

Salaries for Certified Fabric Analytics Engineers in 2026
Being certified in Microsoft Fabric brings considerable career opportunities. Certified professionals are in high demand due to the growing popularity of lakehouse architectures and data analytics solutions. Here’s a rough breakdown of salaries for Fabric Analytics Engineers in the U.S. (2026):
- Entry-Level (0-2 years): $80,000–$95,000 per year
- Mid-Level (3-5 years): $95,000–$115,000 per year
- Senior-Level (5+ years): $120,000–$150,000 per year
Demand for Microsoft Fabric Skills
The demand for professionals skilled in Microsoft Fabric is on the rise. As organizations move towards more cloud-based and scalable analytics solutions, the need for data engineers and analytics engineers has surged. In the U.S., roles such as Fabric Analytics Engineers and Data Architects are expected to grow by 15-20% over the next 5 years.
Future Outlook: The Road Ahead for Fabric Professionals
The DP-600 exam positions you well for advancing in the world of data analytics. Once you’ve passed the DP-600, many professionals move on to the DP-700 (Fabric Data Engineer Expert) for more advanced roles. The future of data engineering looks bright with increasing integration of Fabric with Azure services and the growth of lakehouse architectures.
A Strong Foundation for Senior Roles
As businesses move toward more data-driven decision-making, the demand for senior analytics professionals will continue to grow. The skills you develop while preparing for the DP-600 will set you up for senior roles in the future, particularly in industries leveraging Direct Lake, data governance, and AI-driven analytics.
Conclusion: Ready to Take the DP-600 Exam in 2026?
In summary, the DP-600 exam in 2026 reflects Microsoft’s ongoing commitment to making Fabric a top choice for data analytics and governance. The changes introduced in January 2026 don’t overhaul the exam but refine the focus areas to keep pace with industry needs. With the right preparation—starting with official Microsoft Learn resources, moving into hands-on practice, and utilizing both free and paid practice materials—you’re well-positioned to pass the DP-600 and open up new career opportunities in the world of Microsoft Fabric.
FAQs
1. How long should I prepare for the DP-600 exam?
On average, it takes about 3 to 6 months to adequately prepare for the DP-600 exam, depending on your experience level. If you already have experience with data analytics or Fabric, you may be able to prepare in less time.
2. Can I take the DP-600 exam online?
Yes, the DP-600 exam can be taken online via a proctored session. You’ll need a stable internet connection and a quiet environment to ensure you can complete the exam without interruptions.
3. What are the most important topics to focus on for the DP-600 exam?
The most important topics are data preparation, deployment pipelines, and semantic models. Specifically, make sure you’re familiar with Direct Lake fallback and row-level security as these are critical areas for the 2026 exam.
4. How often is the DP-600 exam updated?
Microsoft typically updates the DP-600 exam every year or two, reflecting changes in the Fabric platform and industry trends. The January 2026 update was a minor one, with more emphasis on deployment pipelines and governance.
5. How does the DP-600 certification impact my career?
The DP-600 certification can significantly enhance your career prospects by opening doors to roles in data engineering and analytics. Certified professionals are in high demand, especially those with expertise in Microsoft Fabric and lakehouse architecture.
